大家好
Suite à la remarque de @Jean2 sur mon poste dédié à la méthode chorusing vs shadowing
j’ai commencé à regarder le logiciel WorkAudioBook qui a l’air magnifique. Malheureusement selon le développeur, Sergey Povalyaev , le logiciel n’est pas et ne sera jamais compatible MacOS / iOS
Avec son accord, j’ai donc commencé à développer un « clone » du logiciel pour Mac, un peu à ma propre sauce. Je l’ai appelé ChorusLab.
EDIT :
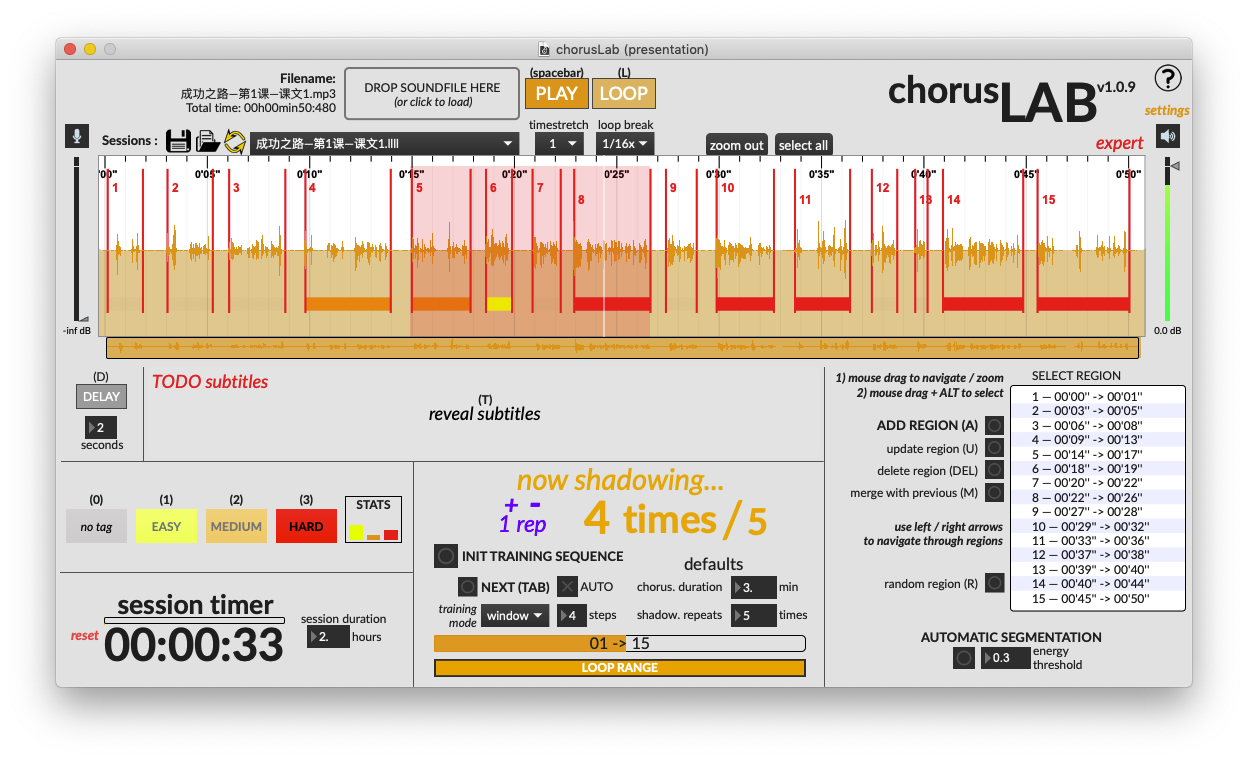
Nouvelle capture d’écran après 3 semaines de développement, dont une de pause bien méritée…
La version 1.0.9 fixe pas mal de gros bugs dont je me suis aperçu en utilisant ChorusLab pour ma propre pratique. J’ai aussi ajouté un mode « window » pour le shadowing. Plus que les sous-titres (差不多 10 jours…) et quelques tests et je pourrai le sortir.
Oui gratuit bien sûr, comme l’autre logiciel pour Windows. Surtout j’aurais pas eu l’idée tout seul, autant que ce soit gratuit et open source.
Je suis musicien pas programmeur, en général les logiciels que je fais il y a un lien Paypal pour payer un tip mais c’est à vot’ bon cœur m’sieurs-dames
c’est très intéressant. Bravo pour ce que cela fait déjà !
Petite idée de fonctionnalité pour la « training session ».
Tu expliques que quand tu arrives à un certain nombre de segments, la partie shadowing devient très longue et que l’on peut baisser le nombre de répétitions.
De mon point de vue, ce n’est pas souhaitable car, dès lors, tu vas encore accentuer le fait de faire plus le début que la fin de l’audio.
Une façon de limiter cela serait de mettre un nombre de segments max dans le shadowing. Dans ton exemple avec 14 segments, en mettant 4 segments max en shadowing, tu aurais :
Et oui je trouve ton idée excellente ! En fait ce serait un variante du « loop range » qui permet déjà de se concentrer sur un partie spécifique. D’ailleurs dans mon idée c’était pour compenser l’ordre des extraits et se concentrer sur la fin justement !
Mais cette idée de « fenêtre glissante » que tu proposes est pas mal car elle permet de réactiver en priorité ce qui vient juste d’être travaillé, sans perdre trop de temps…
Je vais réfléchir à comment l’ajouter prochainement, c’est pas compliqué il me semble !
En fait ce n’était qu’une partie de ce que je voulais dire. Je voulais surtout indiquer que même avec les valeurs par défauts (ex: 3 minutes en chorusing, 5 fois en shadowing) il était possible d’augmenter OU diminuer la durée de travail sur un extrait (les boutons + et - sont toujours présents) pour justement adapter la session avec la difficulté de l’audio, au pifomètre.
Cette question de la fin qui est souvent négligée est intéressante, un copain musicien me l’a fait remarquer l’autre jour. Mais en fait 1) est-ce qu’on est certain que la fin de l’extrait soit ce qui est le plus difficile (pas sûr car souvent les difficultés sont bien réparties) ; 2) est-ce si important au final de négliger un partie? On accepte bien qu’Anki ne nous fasse mémoriser que 80-90%, et c’est déjà énorme
Mais dans l’absolu oui je suis d’accord avec toi, c’est dommage de perdre des bouts. Surtout il faudrait pouvoir être capable de travailler en priorité sur ce qui mérite d’être travaillé, c’est pourquoi je passe pas mal de temps maintenant sur le système de tags.
Pas seulement pour visualiser / garder la trace des difficultés, mais aussi j’imagine de développer la fonction random pour de revenir plus fréquemment sur les extraits taggés « difficile » que « facile » par exemple, avec des probabilités.
Petite mise à jour, le beta-testing privé avance et on se rapproche très rapidement d’une 1ère beta publique !
J’ai ajouté comme prévu un système de tags (easy, medium, hard) pour visualiser / garder la trace des régions à travailler en priorité. Ces tags sont sauvegardés en même temps que les régions sur un fichier qui reste sur le disque, donc en revenant à l’audio dans quelques semaines vous aurez immédiatement un aperçu de quoi retravailler en priorité !
Il y a aussi une nouvelle barre de navigation qui j’espère sera plus intuitive pour zoomer / se déplacer à l’intérieur des audios les plus longs.
Ma TODO list pour les semaines à venir :
ajouter quelques modes de training supplémentaires (suggestion de @Geoffrey )
ajouter un système de « sous-titres » pour synchroniser le texte aux différents fragments. Cette partie n’est pas de tout repos, donc je vais prendre mon temps pour le faire bien !
ChorusLab commence à se stabiliser ! après 10 jours de pause je me suis battu contre un bug vraiment tenace qui est finalement réglé (pour l’instant?).
Et surtout j’ai ajouté le mode « window » suggéré par @Geoffrey, en action dans cette capture d’écran. Ça marche pas mal du tout d’ailleurs, merci encore du conseil !
Encore une petite batterie de tests privés, et surtout je dois m’occuper des sous-titres qui ne sont pas une mince affaire…
Comme d’habitude, si quelqu’un est intéressé à tester, ça me serait très utile !
Salut !
Je débarque tardivement sur ce post, car je cherchais sur le forum de nouvelles manières de continuer à travailler ma prononciation sur des phrases plus longues, au-delà des dictées tonales/mots exercices. J’ai vu ton post sur le chorusing/shadowing, et je me demandais s’il était tjrs possible de tester ton outil ?
Je suis sur MacOS Monterey 12.7
Merci de ton intérêt, même tardif !
À vrai dire je n’y ai pas du tout touché depuis mon dernier post — même pas utilisé, jamais réussi à mettre en place ce genre de routine, sauf avec Glossika.
Je viens de l’ouvrir ici sur 10.14, il fonctionne à peu près comme prévu, mais je garantis pas les fonctions avancées. Mais si tu suis la vidéo de démo ça devrait être bon.
Sur Monterey pas sûr que ça fonctionne tout de suite, à tester :
Si ça ne marche pas, ou si tu as des questions / retours, n’hésite pas. Je me souviens très très vaguement comment ça marchait
Merci j’ai bien pu tester et ça marche sans soucis !
J’ai du temps en ce moment, pour commencer je vais essayer d’en faire environ 1h par semaine on va voir ce que ça donne.
Petite question : il y a une option pour entendre ce qu’on dit dans le micro (à gauche), avec un délai possible, comment est-ce que tu utilisais ton propre enregistrement, tu l’écoutais au fur et à mesure pour vérifier ? Si je réécoute alors même que je suis en train de faire du shadowing ça me perd avec ce que je suis sensée dire.
Ou alors tu t’enregistrais juste avec un autre outil à côté, et tu réécoutais ensuite ?
Ah trop cool ! Bonne nouvelle si ça marche direct sur Monterey…
Oui franchement pour démarrer une heure par semaine c’est bien.
Surtout le chorusing, je pense c’était une erreur de ma part de penser qu’on puisse en faire une ou deux heures d’affilée, c’est trop épuisant à long terme.
Chorusing c’est vraiment un truc que tu peux faire 5 min par jour et ça suffit, l’idée est vraiment de perfectionner ta prononciation, travailler un accent, réparer tes tons ou d’autres problèmes dits « fossilisés », etc.
Le shadowing marche très bien en prolongé par contre, c’est ce que je fais avec Glossika tous les jours (30min jusqu’à 1 heure par fois).
Franchement la fonction avec le micro c’était un test, j’ai pas vraiment eu le temps de l’utiliser. Pour moi c’est pas indispensable, juste un outil de contrôle ponctuel.
Je m’enregistre très peu à vrai dire, cas un peu spécial je suis musicien et ma femme est chinoise (+ on vit en Chine depuis un an) donc j’ai pu constater que la prononciation et les tons ne sont pas un trop gros problème pour moi. Je me concentre surtout sur la syntaxe, le flow, et la mémoire.