Oui c’est une bonne idée
Voici quelques ressources que j’utilise quand je manque d’inspiration pour mémoriser un caractère chinois :
#1 Le livre « remembering simplified Hanzi » est pas mal pour les débutants. Ils proposent des petites histoires sympa pour mémoriser les caractères de base.

Le seul problème c’est que leurs histoires sont complètement déconnectées de celles d’origine. En plus c’est souvent des jeux de mots avec l’anglais, donc ce n’est pas forcément la ressource que je conseillerais par défaut à un francophone.
Mais bon ça reste une bonne introduction à la mnémotechnique !
#2 Le site 字源查询 permet lui au contraire de connaître l’étymologie exacte ainsi que la petite histoire derrière chaque caractère chinois
Par exemple voici la petite histoire pour le caractère 好 :

Par contre il y a 2 problèmes avec ce site :
- Le premier c’est que tout est en chinois. Donc pas du tout adapté aux débutants. C’est dommage parce que c’est quand même cool d’un point de vue culturel de connaître comment certains caractères ont évolué et pourquoi
- Le deuxième c’est que le site vous donnera la véritable histoire derrière chaque caractère. Or certains caractères du quotidien ont tellement évolué qu’ils n’ont plus rien avoir avec leur sens d’origine.
C’est le cas par exemple du caractère 那 dont l’histoire d’origine n’aide pas du tout à s’en souvenir.

#3 Le site Hanzicraft
Ce site est super pratique pour décomposer rapidement un caractère en ses différents radicaux. Par exemple pour le caractère 好 ça donne :
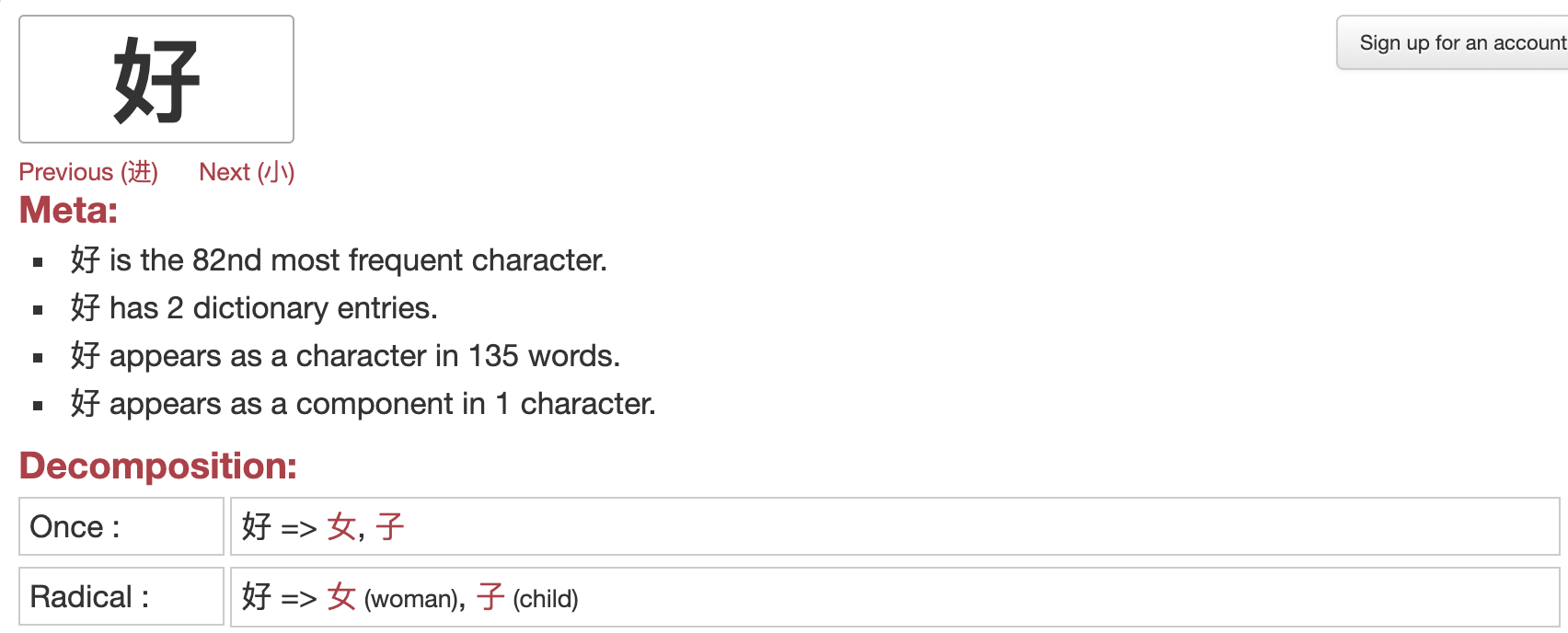
Pratique pour se construire sa propre histoire mnémotechnique quand les 2 ressources citées plus haut ont échoué dans leur job
#4 J’aime bien aussi le site Zhongwen.com

C’est une version plus poussée de Hanzicraft. C’est également un site pratique pour retrouver un caractère à partir de ses radicaux, c’est à dire faire l’inverse d’Hanzicraft (un peu comme si on cherchait le caractère dans un dictionnaire papier).
#5 Le site https://www.chinese-characters.org/

Ce site propose parfois une petite histoire mnémotechnique pour se souvenir des caractères les plus communs. C’est un peu le site que j’utilise quand vraiment je manque d’inspiration
BONUS : Le projet CCC (HORS LIGNE)

Un site avec beaucoup d’illustrations pour mieux visualiser les composants présents dans chaque caractère chinois.
J’aime bien l’idée générale du site qui est de rassembler en un même terme ( C omposants des C aractères C hinois) tous les composants d’un caractère pour pouvoir ensuite mieux les relier à son sens.
C’est d’ailleurs sur ce principe qu’est basée ma méthode RER A qui permet de mémoriser facilement n’importe quel caractère chinois :