Hello,
J’écris pour partager un nouvel outil tout simple que j’ai développé dans Anki. Mais d’abord un peu de contexte…
Ça fait quelques temps que je me suis remis à utiliser de manière intensive le deck « Podcasts » que j’avais créé en suivant la formation intermédiaire d’Alex. À l’époque mon but était juste de me rappeler fréquemment de retravailler un audio — notamment en faisant des dictées. Mais j’ai commencé à avoir la flemme au moment où les audios sont devenus de plus en plus longs. Et puis j’ai lâché l’affaire de l’écriture manuscrite il y a 2-3 ans, quand je suis arrivé en Chine.
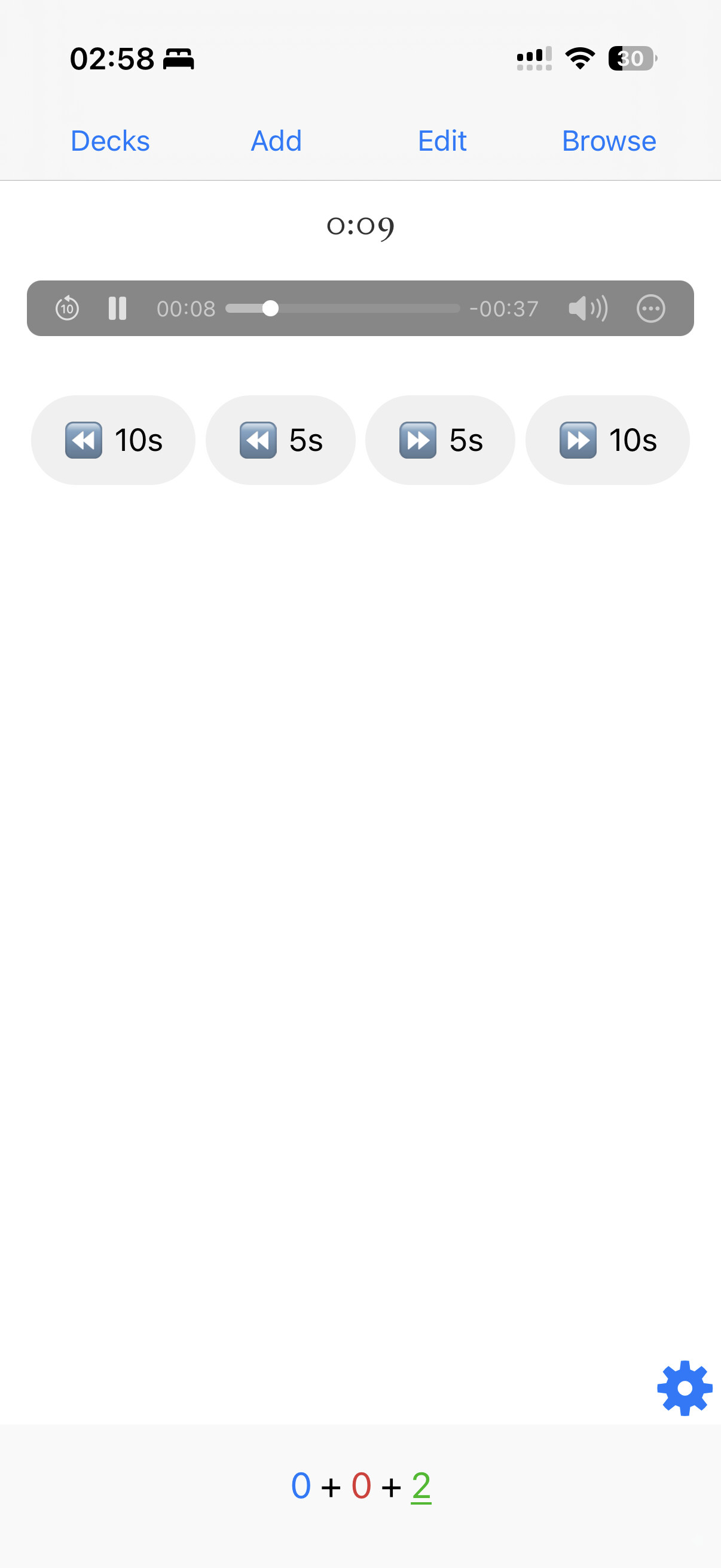
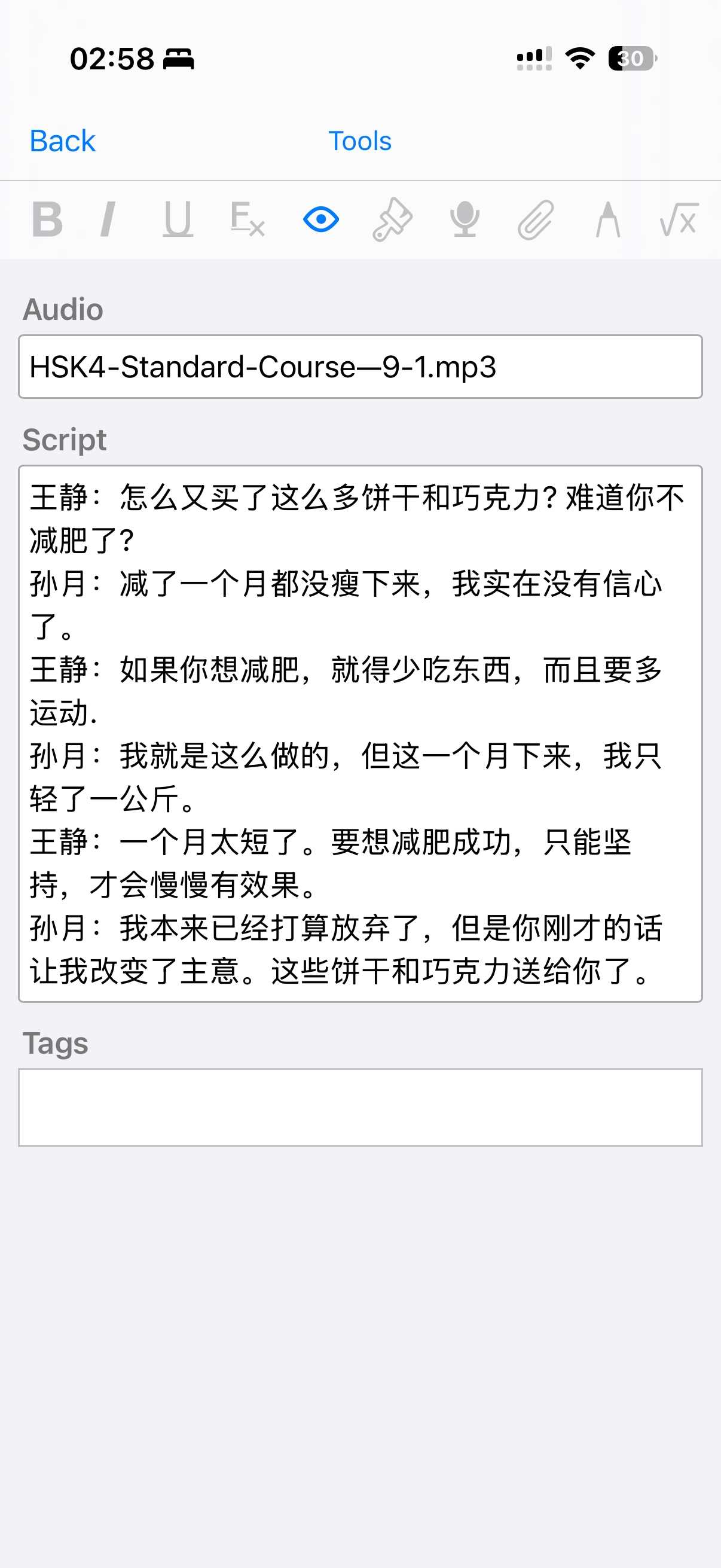
Pour ceux qui ne connaissent pas, ces cartes contiennent deux champs, le nom du fichier audio et le texte qui va avec.
Je suis passé à autre chose en travaillant l’écoute et l’audio surtout via Glossika (dont je viens de me désabonner après 3 ans), méthode « listen and repeat » (presque « chorusing ») par phrases isolées que je continue de suivre gratuitement avec Anki + Chinese Spoonfed ou des phrases que j’isole moi-même d’autres supports comme des séries ou films.
En terme de vocabulaire connu je suis maintenant à 60% de HSK6, mais clairement c’est pas le cas à l’oral…
La méthode par phrases isolées + répétition espacée est très efficace comme exercice quotidien mais on accumule les nouvelles phrases trop lentement. Il faut apprécier de s’ennuyer quelques semaines sur un paquet de phrase avant de vraiment renouveler. Bref ça manque un peu de diversité.
Donc retour aux audios. Pendant 3 ans je me suis focalisé sur les phrases isolées en « listen and repeat » (plutôt grammaire) et le « chorusing » (plutôt orientée prononciation). En supplément, j’écoute des podcasts sans vraiment analyser en détail, juste pour le plaisir. J’écoute et je jette.
Mais une chose que j’ai négligée c’est un travail intensif sur des matériaux de longueur intermédiaire. Je parle d’audios relativement courts (genre 1-2 min) mais en écoute / répétition intensive.
Et là revient l’idée du shadowing, dont j’ai découvert l’existence à l’époque de la formation d’Alex mais que j’avais un peu mal compris. Je reformule donc l’idée ici et je distingue donc bien les deux :
-
chorusing : on répète à l’identique « en chorus » une phrase courte (max 10 secondes) jouée en boucle pendant plusieurs minutes, avec l’audio dans l’oreille tout en se focalisant sur sa propre voix. C’est vraiment un exercise « musculaire », on se focalise sur tous les petits détails du son, 5 minutes par jour c’est redoutable.
-
shadowing : ici on essaye plutôt de répéter après l’audio mais avec une latence autorisée de 2-3 secondes, un peu comme un interprète qui traduit un discours en temps réel. On ne connaît pas forcément le contenu à l’avance, et on peut être amener à se planter, paraphraser, etc.
Pour le shadowing ce qu’on privilégie c’est le discours articulé au delà d’une phrase unique : un paragraphe, plusieurs paragraphes, un chapitre, une histoire entière… Ça peut donc se jouer entre 2-3 minutes. Au delà évidemment il y a les longs podcasts (30 min, 1h…), mais ça me semble plus fatigant à maintenir comme pratique quotidienne, à moins de couper en morceaux bien sûr.